INTERPOLAR
Datenfluss
Ergebnis
Am Ende der Ausführung der Module stehen persistente Daten nur noch in den Tabellen des Schemas “db_log”. Dieses Schema bzw. dessen Tabellen bilden den Kern der Datenbank, die alle Datensätze sowie Zeitstempel zu deren Gültigkeit dauerhaft speichert. Das gilt für alle 3 Module, die Daten zur Datenbank hinzufügen (“cds2db”, “dataprocessor” und “db2frontend”). Jegliche Operationen in den Modulen beziehen sich immer auf den zuvor im Kern (Schema “db_log”) gespeicherten Datenstand, um eine Nachvollziehbarkeit zu gewährleisten. Damit kann es eine zeitliche Abhängigkeit zwischen den Modulen / Prozessschritten geben, bis das “db_log” Schema bedient ist. Jede Zuführung von Daten in den Schnittstellen wird gespeichert und jede Datenausgabe über die Schnittstelle lässt sich im Nachhinein zu einem bestimmten Zeitpunkt rekonstruieren.
Voraussetzungen / Vorbereitung
Die nun beschriebene Initialisierung wurde vom Entwicklerteam einmalig bzw. immer wenn sich an der Struktur der Datenbank etwas geändert hat, ausgeführt. Dieser Abschnitt dient nur der Vollständigkeit und die darin beschriebenen Abläufe werden nur einmal beim Initialisieren der SQL-Skripte zum Anlegen der Datenbank (“CDS Hub DB”) ausgeführt. Im Betrieb, also dem eigentlichen Ausführen der “CDS tool chain”, werden sie nicht benötigt.
Zur Initialisierung des Prozesses musste die Excel-Datei Table_Description_Definition.xlsx definiert werden. Sie bildet den tatsächlichen COI und gibt vor, wie die FHIR-Abfragen gestellt werden und wie die Datenbank zur Speicherung der Ergebnisse dieser Abfragen aufgebaut ist.
Mithilfe eines R-Generatorskriptes wird aus der wesentlich übersichtlicheren “Table_Description_Definition.xlsx” die vollständige Table_Description.xlsx expandiert. In dieser generierten Datei stehen alle abgefragten FHIR-Ressourcen sowie alle absoluten XML-Pfade dieser Ressourcen, die am Ende als Spalten in die jeweilige Tabelle in die Datenbank geschrieben werden.
Nachdem die vollständige “Table_Description.xlsx” vorliegt, werden mit einem weiteren Generatorskript unter Benutzung vorher definierter SQL-Templates wesentliche Teile der Datenbankskripte generiert, die die Tabellen der Postgres-Datenbank zur Speicherung der FHIR-Abfragen und Funktionen innerhalb der Datenbank anlegen.
Diese beiden Generatorskripte liegen auch im R-Verzeichnis des im folgenden beschriebenen Moduls “cds2db”. Die SQL-Templates sowie die fertigen SQL-Skripte befinden sich im “init”-Verzeichnis des Moduls “cds_hub”.
Das Vorgehen stellt sicher, dass die umfangreichen FHIR-Abfragen und Strukturen immer genau zur Datenbank passen und sich bei Bedarf einfach anpassen lassen.
Analog werden die Strukturen und Überführungsfunktionen für das Frontend mit SQL-Skripten bei der Initialisierung angelegt. Derzeit werden diese Skripte nicht über Templates generiert, sondern sind statisch hinterlegt.
Übersicht über alle Module
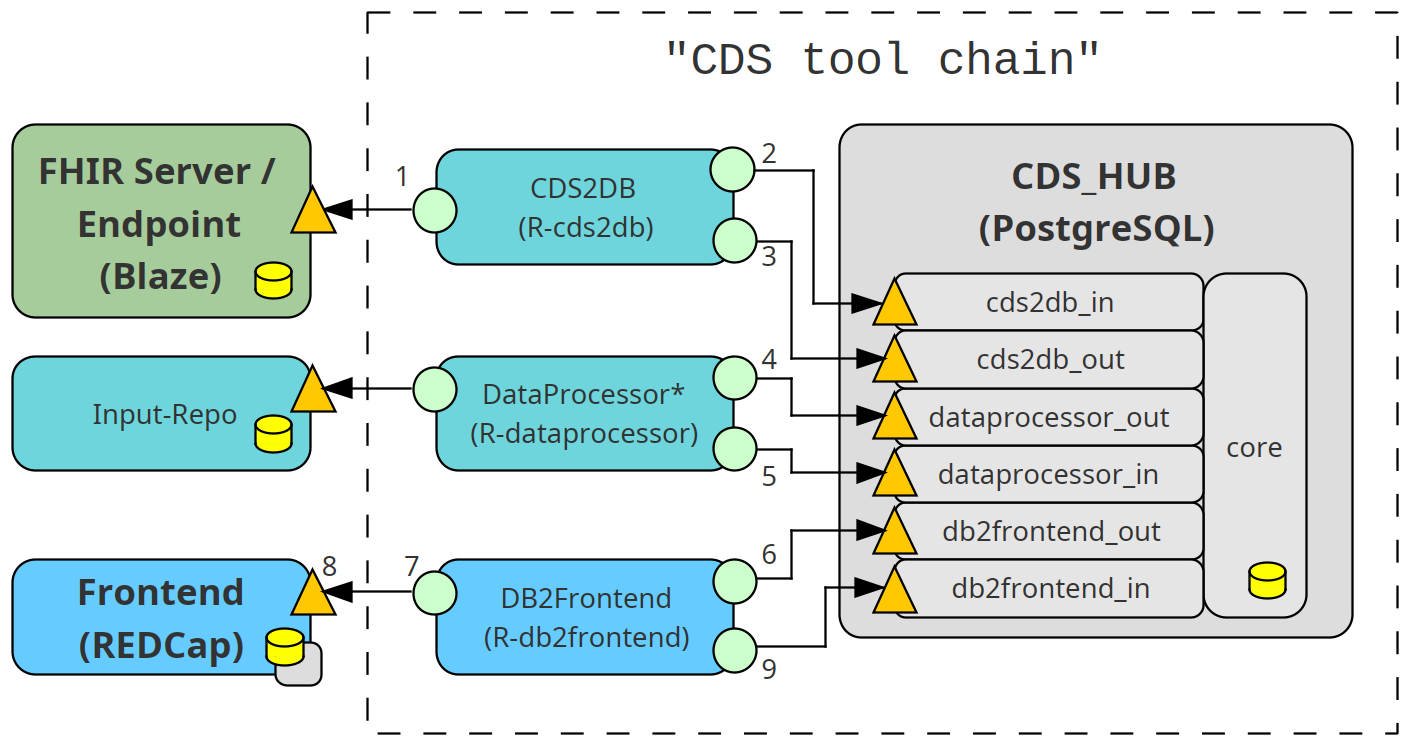
Im Folgenden werden sowohl der in der Grafik mit Zahlen markierte Datenfluss zwischen den Modulen als auch der Datenfluss innerhalb der Module beschrieben.
Modul “cds2db”
FHIR Patienten ID Filterung
Als allererstes werden bei der Ausführung des Moduls “cds2db” die Interpolar-relevanten Patienten-IDs (Resource-IDs der Patienten auf dem FHIR-Server) mit ihrer entsprechenden Stationszugehörigkeit ermittelt. Dies kann auf 2 Weisen erfolgen:
- Über die Verbindung 1 in der Grafik werden die IDs anhand von Filtern, die in der zugehörigen Konfigurationsdatei für die jeweiligen Stationen definiert wurden, ermittelt. Diese Einstellungen und zugehörige Erklärungen befinden sich im Abschnitt “[retrieve.patient_id_filtering]”.
- Es wird eine Textdatei mit entsprechendem Inhalt bereit gestellt. Der Pfad zur Textdatei wird im selben Abschnitt auch in der Konfigurationsdatei definiert. Wenn dieser Pfad aktiviert ist, ist Variante 1 automatsch deaktiviert - egal ob Filter definiert sind. Ein Beispiel für eine solche Datei findet sich unter source_PIDs.txt.
Wichtig: Die Namen der Stationen, die am Ende im Frontend angezeigt werden, entsprechen genau den Namen der Stationen in den Filtern bzw. in der Textdatei.
Abfrage der Daten vom FHIR Server und Speicherung als RAW-Daten
Der FHIR-Server wird nun anhand der oben beschriebenen, vollständig expandierten “Table_Description.xlsx” abgefragt (Verbindung 1 in der Grafik) und die Daten durch den “fhircrackr” von ihrer XML-Struktur in flache Tabellen umgewandelt.
Zuerst werden über das Schema “cds2db_in” diese Daten in dessen Tabellen mit dem Suffix “_raw” geschrieben (Verbindung 2 in der Grafik). Dabei wird der Zeitstempel des Einfügens “input_datetime” hinzugefügt. Die Tabellen heißen wie die FHIR-Ressourcen, außer die spezielle Tabelle “pids_per_ward_raw”, die die aktuellen Patienten IDs der Interpolarstationen und eine Zuordnung zum Stationsnamen speichert. Danach läuft in regelmäßigen Abständen ein Cron-Job und überprüft die importierten Daten auf neue bzw. aktualisierte Datensätze. Der Default für diese Abstände beträgt 1 Minute und ist in den SQL-Skripten hinterlegt, die die Datenbank erzeugen.
Bei neuen Datensätzen, werden diese in die gleich heißenden Tabellen des “db_log” Schemas verschoben und damit aus den Tabellen des “cds2db” Schemas entfernt.
Bei Daten, welche bereits schon einmal in die Tabellen des “db_log” überführt wurden, wird nur die Spalte “last_check_datetime” aktualisiert.
Nach Ausführung des Cron-Jobs stehen nur noch Daten in “db_log” Tabellen. Sollten Fehler beim Überführen durch den Cron-Job auftreten, verbleibt der betroffene Datensatz in der “_raw” Tabelle. Dann wird bei der nächsten Ausführung erneut versucht, diesen Datensatz zu verarbeiten.
Dieses Vorgehen stellt sicher, dass alle Datensätze vorhanden sind, aber eben nur ein mal und bekannt ist, wann der Datensatz das erste und das letzte Mal aus einer Abfrage vom FHIR-Server zurückkam.
Die RAW-Daten sind genau die vom FHIR-Server heruntergeladenen Ressourcen, die nur durch den “fhircrackr” geleitet wurden. Also die größtmöglich unveränderten Daten vom Server.
Nach dem Schreiben der RAW-Daten in die Datenbank durch das R-Script wartet das Script ca. 1 Minute, um sicher zu stellen, dass der oben genannte Cron-Job mit dem Verschieben in den Kern der Datenbank gelaufen ist.
Zerlegung und Typsisierung der Daten
Danach macht das R-Script damit weiter, mit dem Schema “cds2db_out” über Views alle neuen RAW-Daten aus den “db_log”-Tabellen abzurufen (Verbindung 3 in der Grafik). Neu heißt, dass der nun folgende Zerlegungs- und Typisierungsprozess diese Daten noch nicht zerlegt und typisiert hat, was an den jeweiligen primary keys der Ursprungsdaten erkannt wird.
Diese Zerlegung ist ein Prozess, der im “fhircrackr” fhir_melt() heißt. In den RAW-Daten nehmen nach dem fhir_crack() alle Ressourcen immer genau nur 1 Zeile in der Tabelle der jeweiligen Ressource ein. Wenn diese Ressource aber eine Liste von Unterelementen hat (z.B. Encounter hat eine Liste von Referenzen auf mehrere Diagnosen (Conditions)), dann stehen diese mit einer speziellen Klammerung und in den Klammern enthaltenen Indizes durch Tilde (“ ~ “) getrennt in der zugehörigen Spalte.
Diese Klammerung und Indizes müssen nun alle in eigene Zeilen aufgespaltet werden, um die Einzelwerte in den Listen zu erhalten. Dabei werden alle anderen Daten der Zeile jeweils dupliziert. Da diese Listen an vielen Stellen auftauchen, der Vorgang generisch umgesetzt ist und dieses fhir_melt() eine recht teure Operation ist, dauert dieser Punkt unter Umständen etwas länger.
Wenn alle Listen in eigene Zeilen zerlegt sind, dann können sie typisiert werden. Bis dahin waren alle Raw-Daten Strings (bzw. in R character). Anhand der Table_Description.xlsx werden nun alle nicht-String-Daten in Zahlen, Datumsangaben, Uhrzeiten usw. umgewandelt.
Nach der Umwandlung werden die nun fertig aufbereiteten Daten wieder über das Schema “cds2db_in” in die zugehörigen Tabellen ohne den “_raw”-Suffix geschrieben (wieder über Verbindung 2 in der Grafik). Danach erfolgt eine Überführung der Daten mittels eines weiteren Cron-Jobs in den Kern der Datenbank (“db_log”) analog zur “Speicherung als RAW-Daten”.
Damit ist das Modul “cds2db” fertig und der “dataprocessor” kann starten (allerdings sollte dazwischen auch mind. 1 Minute liegen, damit die Daten zuverlässig im Kern vorliegen).
Modul “dataprocessor”
Der Dataprocessor erstellt aus den vom “cds2db” Modul importierten, im Kern der Datenbank gespeicherten Daten die Ausgabetabellen für das Modul “frontend”. Dafür holt das Modulüber das Schema “dataprocessor_out” und dessen Views Daten aus dem Kern der Datenbank (Verbindng 4 in der Grafik) und schreibt seine Ergebnisse zurück in die Tabellen des Schemas “dataprocessor_out” (Verbindung 5 in der Grafik).
Im Moment sind das die Tabellen “patient_fe” und “fall_fe” (“_fe” - Daten für “Frontend”). Auch hier werden die Daten wieder durch einen Cron-Job in den Kern (“db_log”) in Tabellen mit demselben Namen verschoben und persistiert. Erst danach stehen diese dem Frontend zur Verfügung.
Bei der Erzeugung aller Daten werden immer Primärschlüssel der “Quell”-Datensätze mit in den Daten gespeichert, um über Referenzierung letztendlich bis auf den ursprünglichen FHIR-Datensatz (-Stand) schließen zu können.
Die Tabelle “patient_fe” sollte alle Patienten enthalten, deren FHIR-interne ID, wie im Abschnitt “FHIR Patienten ID Filterung” beschrieben, ermittelt wurden.
Die Tabelle “fall_fe” sollte eine Liste aller Fälle enthalten, die für Patienten mit den oben genannten IDs aktuell laufen.
Voraussetzung: Das aktuelle Datum muss zu den Start- und Enddaten der Encounter passen. Es werden nur Fälle gefunden, deren Startdatum vor dem aktuellen Datum liegt und deren Enddatum nach dem aktuellen Datum liegt oder nicht gesetzt ist.
Will man hier für Daten aus der Vergangenheit irgendwas sehen, dann muss in der Konfigurationsdatei für den Dataprocessor (dataprocessor_cofig.toml) unter der Variable “DEBUG_ENCOUNTER_DATETIME” ein entsprechend zu den Daten passendes Datum eingestellt werden. Alle Variablen, die im Echtbetrieb deaktiviert sein sollten, haben den Präfix “DEBUG_”.
Module “db2frontend” und “frontend”
Die Datenbank stellt dem Frontend die im Modul “dataprocessor” erzeugten Daten im Schema “db2frontend_out” zur Verfügung (Verbindung 6 in der Grafik). Die Schnittstelle zwischen dem Modul “frontend” (hier “RedCap”) und der Datenbank wird wieder durch ein R-Script realisiert (Verbindungen 6 und 7 in der Grafik). Nach der Ausführung des jeweiligen Skripts (R-Skript) zum Datenaustausch mit dem Frontend werden diese in der Oberfläche angezeigt und können bearbeitet werden. Danach können neue bzw. geänderte Daten im Schema “db2frontend_in” wieder in die “CDS Hub DB” geschrieben werden (Verbindungen 8 und 9 in der Grafik). Dies erfolgt analog zum Modul “dataprocessor” und am Ende werden die Daten in den zugehörigen Tabellen im Schema “db_log” dauerhaft gespeichert.
Auch in diesem Modul werden Primärschlüssel der “Quell”-Datensätze an das Frontend mit übergeben, um beim Reimport der geänderten Daten einen Zusammenhang herstellen zu können.
Steuerung innerhalb der Datenbank (Semaphore)
In der Datenbank erfolgt die Übertragung von Daten zwischen den verschiedenen Modulen und dem Datenbankkern automatisch durch einen Cron-Job. Damit neue Daten stets in ihrem zeitlichen Zusammenhang verarbeitet werden (nur vollständige Übertragungen) und einem konsistenten Zeitpunkt zugeordnet werden können (identische Processing-Nummer), wurde ein Semaphore-Mechanismus eingeführt. Dieser ermöglicht es, dass R-Skripte in den Modulen den Cron-Job pausieren und wieder starten können (siehe 95_cron_job.sql).
Die Semaphore kennt die folgenden Zustände:
1. WaitForCronJob
In diesem Zustand müssen alle Übertragungsaktionen durchgeführt werden. Die Verarbeitung startet automatisch mit der nächsten Instanz des Cron-Jobs (Standardintervall: jede Minute).
2. Ongoing
Die Übertragungsaktionen werden aktuell ausgeführt. Alternativ kann ein externer Prozess die Verarbeitung angehalten haben, um auf einen konsistenten Datenstand lesend oder schreibend zuzugreifen.
3. ReadyToConnect
Ein externer Prozess kann diesen Zustand setzen, um die Verarbeitung zu pausieren. Die Dauer der Pause ist über die Parameter konfigurierbar (siehe 03_db_parameter.sql).
4. Interrupted
In diesem Zustand wurde die Verarbeitung vollständig durch einen Administrator unterbrochen.
Mit dieser Mechanik wird sichergestellt, dass die Datenintegrität während der Verarbeitung gewährleistet bleibt, insbesondere bei parallelen Zugriffs- und Schreiboperationen.