INTERPOLAR
Datenbankbeschreibung CDS-HUB DB (cds_hub_db)
Überblick
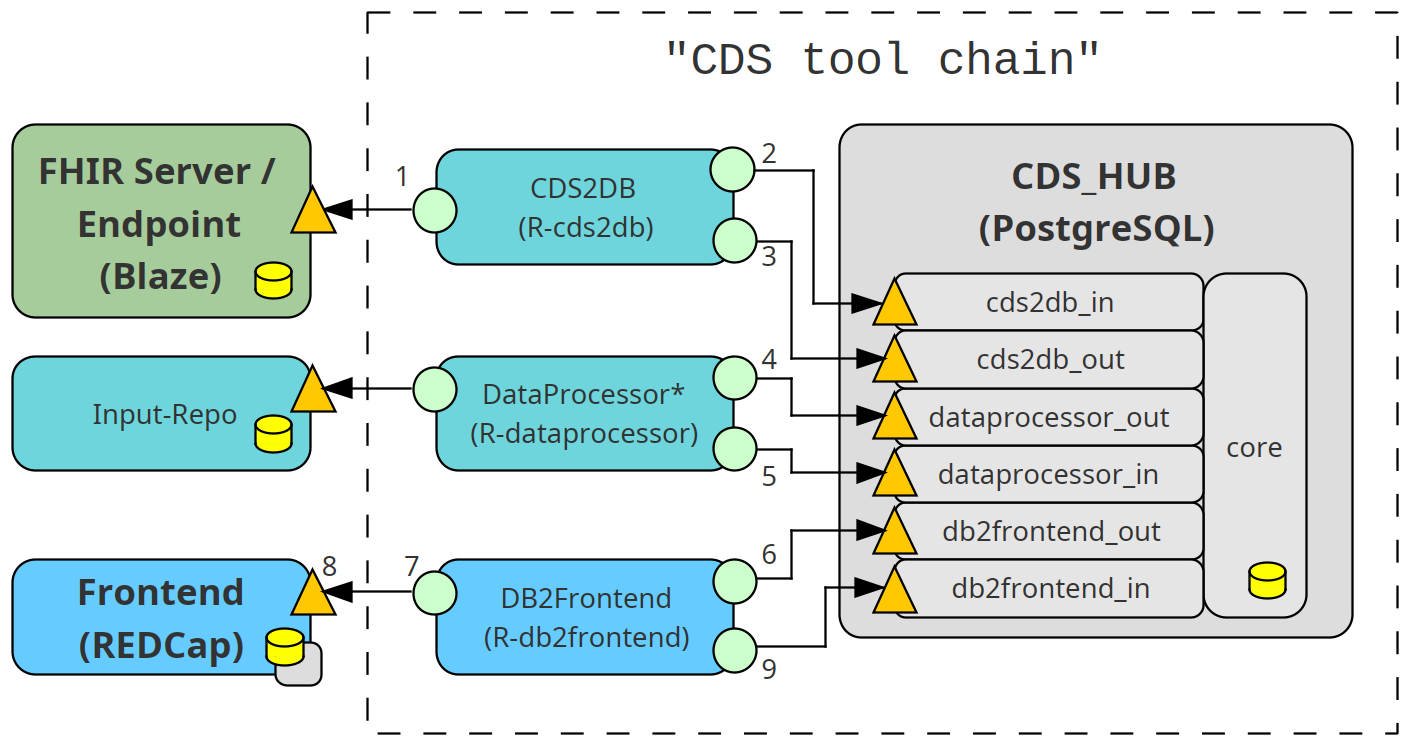
Die CDS-HUB DB dient dazu die importierten FHIR-Daten sowie die erhobenen Studiendaten des Zentrums für spätere Auswertungen persistent zu speichern. Die Datenbank enthält für verschiedene Aufgaben und Zugriffsrollen mehrere Bereiche. Sie beinhaltet nur rudimentäre Logik, die ausschließlich der dauerhaften Speicherung der Daten (Logging) sowie der Bereitstellung der aktuellen Daten an den Schnittstellen dient.
Arten der Daten
In der CDS-HUB DB werden verschiedene Arten von Daten gespeichert. Diese unterscheiden sich entweder im Verwendungszweck oder dem Verarbeitungsstatus. Als Verwendungszweck gibt es alle Daten, die mit FHIR (also der Datenquelle), der Studiendokumentation (also Daten zum Anzeigen/Bearbeiten), organisatorischer Natur, sind (Parameter, Konfigurationen usw.) oder eine Logging davon sind (Siehe auch Bereiche /Schnittstellen). Beim Verarbeitungsstatus kann im besonderen bei dn FHIR Daten von den originalen importierten Daten (Endung “_raw”) und den dann daraus generierten Daten in relationaler Form unterscheiden werden. Dabei ist eine Referenzierung und Rückverfolgung mit Schlüsseln durch die Datenbank gegeben (siehe Beschreibung Datenfluss).
Bereiche / Schnittstellen
Man kann die verschiedenen Bereiche (Schemata) in Schnittstellenschemata und funktionale Schemata unterscheiden. Die Schnittstellenschemata dienen dem sicheren Austausch von Daten mit den jeweiligen ‘externen’ Modulen und dem damit verbundenen Rollen- und Rechtekonzept. Deshalb sind Daten in diesen Schemata nur temporär enthalten und werden von der Datenbank von dort ‘weg’ kopiert bzw. neu zur Verfügung gestellt.
Funktionale Schemata dienen der inhaltlichen Gliederung der Daten innerhalb der Datenbank. Im Folgenden werden die verschiedenen Bereiche der CDS-HUB DB vorgestellt.
cds2db_in / cds2db_out
Schnittstellen-Schema zum Importieren von FHIR-Daten (_in) sowie zur Umwandlung dieser Daten in typisierte relationale Datenbanktabellen. Die Umsetzung erfolgt in dieser Referenzimplementierung im Modul CDS2DB mithilfe von R-Skripten (R-cds2db ). Die in diesem Schema angelegten Tabellen entsprechen den Strukturen der FHIR-Ressourcen.
db2dataprocessor_in / db2dataprocessor_out
Schnittstellen-Schema, um zum einen Daten aus dem Kern dem Modul DataProcessor (_out) zur Verfügung zu stellen und zum anderen berechnete Daten von diesem entgegenzunehmen (_in) und wieder im Kern dauerhaft zu speichern. Sämtliche inhaltliche Logik und Berechnungen finden im Modul DataProcessor statt und können z. B. über R-Skripte implementiert werden (R-dataprocessor). Die in diesem Schema angelegten Tabellen entsprechen den Strukturen der FHIR-Ressourcen (_out) sowie den Strukturen, die fürs Frontend benötigt werden. Weitere Tabellen können für zusätzliche Funktionalitäten erforderlich werden.
db2frontend_in / db2frontend_out
Schnittstellen-Schema, um Daten aus dem Kern an ein Frontend zu übergeben (_out) bzw. von diesem entgegenzunehmen (_in) und im Kern zu speichern. Die in diesem Schema angelegten Tabellen entsprechen den Strukturen des Frontends.
Kern
Im Kern der Datenbank werden alle Daten gespeichert sowie verschiedene Cron-Jobs zur Ausführung der Datenbankfunktionalitäten betrieben. Der Kern unterteilt sich in weitere Bereiche, um die Daten thematisch voneinander zu trennen.
db
Kern der Datenbank mit individuellen Studienspeziefischen Tabellen. Dies ergeben sich aus der Studienanforderung und können beiuspielsweise Zwischenergebnisse oder Aggregationen sein.
db_log
Schema zur Speicherung aller Daten so das diese zu jedem Zeitpunkt nachvollzogen werden können. Logging der Daten und Datenänderungen. Die genauen Tabellenstrukturen ergeben sich generisch aus den Anforderungen der FHIR-Daten, der Struktur des Frontends sowie den jeweiligen Studienvorgaben.
db_konfig
Schema zur Speicherung von Hilfstabellen, Hilfs-Views, Tabellen für individuelle Standort-Parameter (zB. Zeitformat, DB-Job-Intervalle etc.).
Rechtekonzept
Die Zugriffskontrolle auf die verschiedenen Bereiche und somit auf Daten und Funktionalitäten erfolgt über verschiedene Datenbanknutzer. Jede Schnittstelle besitzt einen eigenen Datenbanknutzer, der exakt die Berechtigungen hat, die für die jeweilige Schnittstelle erforderlich sind. Die Berechtigungen sind so konfiguriert, dass die Nutzer der Schnittstellen nur Daten innerhalb des jeweiligen Schnittstellenbereichs ändern können. Diese Datenbanknutzer sind für den Austausch mit anderen Modulen vorgesehen.
Im Kern der Datenbank verfügen weitere Datenbanknutzer über Berechtigungen, um Daten aus den Schnittstellen zu lesen, zu archivieren und für die Schnittstellen bereitzustellen. Diese Datenbanknutzer, insbesondere der Administrator-Nutzer, sollten nur den für die Datenbank verantwortlichen Personen zugänglich sein.
| DB-Nutzer | Bereich | Lesen (Select) | Schreiben (Insert) | Ändern (Update) | Löschen (Delete) |
|---|---|---|---|---|---|
| cds2db_user | cds2db_in | x | |||
| cds2db_user | cds2db_out | x | |||
| db2dataprocessor_user | db2dataprocessor_in | x | |||
| db2dataprocessor_user | db2dataprocessor_out | x | |||
| db2frontend_user | db2frontend_in | x | |||
| db2frontend_user | db2frontend_out | x | |||
| db_log_user | cds2db_in | x | |||
| db_log_user | db2dataprocessor_in | x | |||
| db_log_user | db2frontend_in | x | |||
| db (Kern) | db_log | x | x | x | |
| db (Kern) | cds2db_in | x | x | x | |
| db (Kern) | db2dataprocessor_in | x | x | x | |
| db (Kern) | db2frontend_in | x | x | x | |
| Admin | * alle | x | x | x | x |
Datenfluss
Die CDS-HUB DB ist ein Bestandteil des Datenflusses. Daher ist der Beschreibung des ‘normal’ vorgesehenen Datenflusses eine ausführliche und umfassende Beschreibung gewidmet (Datenfluss).
Um den Datenfluss zu gewährleisten und rückverfolgbar zu machen, werden zu allen Daten (Tabellen) immer datenbankinterne technische Primärschlüssel angelegt und gegebenenfalls bei der Verarbeitung weitergegeben. Diese technischen Primärschlüssel können redundant zu den in den Daten enthaltenen Primärschlüsseln sein (z. B. FHIR-IDs).
Erzeugung der Datenbank
Bei der initialiesierung der Datenbank ist die Ausführung des Skriptes zum anlegen von Schemata und Rollen bereits konfiguriert (siehe Postgres-cds_hub/init (SQL-Skripte)).
Danach ist die Strukturen und Funktionalität der Datenbank zu erzeugen, dies funktioniert wie eine Migration und ist weiter unten im Zugehörigen Abschnitt beschrieben.
Der genaue Inhalt ist im jeweiligen SQL-Skript nachzulesen (siehe Postgres-cds_hub/init (SQL-Skripte)).
Teilweise werden diese Skripte mit Hilfe von Templates und Konfigurationsdateien erzeugt. Dies betrifft alle Skripte zum Anlegen von Tabellen und deren Spalten. Die Definition der Tabellen für das Modul ‘cds2db’ (insbesondere die Definition der Tabellen für die FHIR Ressourcen) finden sich in der Datei Table_Description.xlsx. Die Definition der Tabellen für das Modul ‘frontend’ sind in der Datei Frontend_Table_Description.xlsx angegeben. Zusätzlich dazu gibt es noch eine Definition der Tabellenschemata und Rechte, die im Generierungsprozess benötigt wird (siehe User_Schema_Rights_Definition.xlsx) sowie die eigentlichen Templates im selben Ordner. Durch das R-Script Init_02_Create_Database_Scripts.R wird der generierte Teil der SQL-Scripte erzeugt und in /base zur späteren ausführung abgelegt.
Bei der Initalisierung bzw. Migratin (start.sql) der Datenbank ist darauf zu achten das alle Skripte fehlerfrei ausgeführt werden, um die Funktionalität zu gewährleisten.
001_main_user_schema_sequence (/sql/init)
Initialisierung aller Schemata, Nutzer und Sequenzen. Passwörter für die verschiedenen Datenbanknutzer der Bereiche (Module / Schnittstellen) sind hier zu setzen.
020_db_config_tools (/sql/base)
Allgemeines Skript zur Anlage von Hilfsansichten oder Hilfs-Jobs, z.B. eine Übersicht der Cron-Jobs oder der Bereinigung von Cron-Job-Berichten.
030_db_parameter (/sql/base)
Allgemeines Skript zum anlegen und initialiesieren von Parametern. Teils allgemein teils Standortspeziefisch (ab Release v0.2.5).
035_db_log_table_structure (/sql/base)
Tabelle und Funktion um die Strucktur ((Tabellen, Views, Funktionen, Trigger)) der CDS-HUB Datenbank über die beteiligten Schemata hinweg unabhängig zu dokumentieren. Diese Änderungen können bei einer späteren Auswertung helfen, Migrationsübergänge besser festzustellen und zu berücksichtigen.
100_cre_table_raw_cds2db_in (/sql/base)
Erstellen der Strukturen für die FHIR-Daten (Rohdaten) im Importschema cds2db_in. Dabei werden eindeutige Primärschlüssel vergeben sowie die Berechtigungen für die zugehörigen Datenbankbenutzer gesetzt.
120_cre_table_raw_db_log (/sql/base)
Erstellen der Strukturen zur dauerhaften speicherung für die FHIR-Daten (Rohdaten) im Kern (db_log) sowie Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
140_cre_table_typ_cds2db_in (/sql/base)
Erstellen der Strukturen für die FHIR-Daten nach dem diese typiesiert und aufgeschlüsselt wurden (Verwendbare Daten) im Importschema cds2db_in. Dabei werden eindeutige Primärschlüssel vergeben, die technischen Primärschlüssel der Raw-Daten referenziert sowie die Berechtigungen für die zugehörigen Datenbankbenutzer gesetzt.
150_get_last_processing_nr_typed (/sql/base)
Generierte Funktion um die letzte Prozessingnuber der Daten im Kern zu ermitteln (Verarbeitungsnummer des letzten konsistenten Datenstandes).
160_cre_table_typ_log (/sql/base)
Erstellen der Strukturen für die FHIR-Daten nach dem diese typiesiert und aufgeschlüsselt wurden (Verwendbare Daten). Um diese dauerhaft im Kern (db_log) zu speichern. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
180_cre_view_typ_raw_type_diff_log (/sql/base)
Erstellt Views im Schnittstellenschema cds2db_out um alle Datensätze zu listen, welche bereits als Raw-Daten im Kern dauerhaft gespeichert wurden, jedoch noch nicht typiesiert und aufgeschlüsselt sind (Erkennung über tecnische Datenbankinterne Primrschlüssel). Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
190_cre_view_typ_dataproc_all (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um alle verwendbaren (getypten, aufgeschlüsselt) FHIR-Daten dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
190_cre_view_typ_dataproc_last_import (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um von allen jemals importierten FHIR-Daten (raw) die letzte Version anzuzeigen. Wird in der Funktion db.add_hist_raw_records() (siehe 250_adding_historical_raw_records) verwendet um den Import der FHIR Daten zu optimieren indem durch abgleich des Zeitstempels der letzten Änderung doppeltes Nachladen vermieden wird. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer
200_take_over_check_date (/sql/base)
Funktion welche in den Datensätzen übergreifend dokumentiert in welchem Zeitraum die Datensätze barbeitet wurden - mit (Start- / Last-) Processing-Nr.
210_cre_view_typ_cds2db_all (/sql/base)
Erstellt Views im Schnittstellenschema cds2db_out um Daten die für den Import der FHIR Daten notwenig sind zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
220_cre_view_raw_cds2db_last_import (/sql/base)
Erstellt Views im Schnittstellenschema cds2db_out um die beim letzten Import übertragenen Raw-Daten anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
230_cre_view_raw_cds2db_last_version (/sql/base)
Erstellt Views im Schnittstellenschema cds2db_out um von allen jemals importierten FHIR-Daten (raw) die letzte Version anzuzeigen. Wird in der Funktion db.add_hist_raw_records() (siehe 250_adding_historical_raw_records) verwendet um den Import der FHIR Daten zu optimieren indem durch abgleich des Zeitstempels der letzten Änderung doppeltes Nachladen vermieden wird. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
230_cre_view_raw_dataproc_last_version (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um von allen jemals importierten FHIR-Daten (raw) die letzte Version anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
230_cre_view_typ_cds2db_last_version (/sql/base)
Erstellt Views im Schnittstellenschema cds2db_out um von allen jemals importierten FHIR-Daten die getypt wurden die letzte Version anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
230_cre_view_typ_dataproc_last_version (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um von allen jemals importierten FHIR-Daten die getypt wurden die letzte Version anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
250_adding_historical_raw_records (/sql/base)
Erstellt die Funktion db.add_hist_raw_records() um den Import der FHIR Daten zu optimieren indem durch abgleich des Zeitstempels der letzten Änderung doppeltes Nachladen vermieden wird.
300_cds_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_raw_cds_in_to_db_log) für die FHIR-Daten vom Schnittstellenschema cds2db_in in den Kern (db_log) für die Raw-Daten. Nach anlegen der Funktion wird ebenfalls der Cron-Job angelegt und gestartet, der die Funktion regelmäßig ausführt.
310_cds_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_type_cds_in_to_db_log) für die FHIR-Daten vom Schnittstellenschema cds2db_in in den Kern (db_log) für die getypten und aufgeschlüsselten Daten. Nach anlegen der Funktion wird ebenfalls der Cron-Job angelegt und gestartet, der die Funktion regelmäßig ausführt.
330_cre_table_dataproc_submodules_dataproc_in (/sql/base)
Erzeugen der Tabellen für die Submodule des Dataprocessor welche in der Tabelle /R-dataprocessor/submodules/Dataprocessor_Submodules_Table_Description.xlsx definiert werden (Dataprocessor-In Schema).
331_cre_table_dataproc_submodules_log (/sql/base)
Erzeugen der Tabellen für die Submodule des Dataprocessor welche in der Tabelle /R-dataprocessor/submodules/Dataprocessor_Submodules_Table_Description.xlsx definiert werden (Kern db_log).
332_db_submodules_dp_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_submodules_dp_in_to_db_log) für die berechneten Daten der Submodule des Dataprocessors aus dem Schnittstellenschema db2dataprocessor_in in den Kern (db_log).
334_cre_view_dataproc_submodules_last_import (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um die beim letzten Import/Berechneten Daten der Dataprocessor Submodule anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
335_cre_view_dataproc_submodules_all (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um alle Berechneten Daten der Dataprocessor Submodule anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
340_cre_table_dataproc_core_dataproc_in (/sql/base)
Erzeugen der Tabellen für die Kernmodule des Dataprocessor welche in der Tabelle /R-dataprocessor/dataprocessor/inst/extdata/Dataprocessor_Table_Description.xlsx definiert werden (Dataprocessor-In Schema).
341_cre_table_dataproc_core_log (/sql/base)
Erzeugen der Tabellen für die Kernmodule des Dataprocessor welche in der Tabelle /R-dataprocessor/dataprocessor/inst/extdata/Dataprocessor_Table_Description.xlsx definiert werden (Kern db_log).
342_db_core_dp_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_core_dp_in_to_db_log) für die berechneten Daten der Kernmodule des Dataprocessors aus dem Schnittstellenschema db2dataprocessor_in in den Kern (db_log).
344_cre_view_dataproc_core_last_import
Erstellt Views im Schnittstellenschema db2dataprocessor_out um die beim letzten Import/Berechneten Daten der Dataprocessor Kernmodule anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
345_cre_view_dataproc_core_all (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um alle Berechneten Daten der Dataprocessor Kernmodule anzuzeigen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
400_cre_table_typ_dataproc_in (/sql/base)
Erstellen der Strukturen für die durch den Dataprocessor erstellten Daten für das Frontend im Schnittstellenschema db2dataprocessor_in. Dabei werden eindeutige Primärschlüssel vergeben, die technischen Primärschlüssel der FHIR-Daten referenziert sowie die Berechtigungen für die zugehörigen Datenbankbenutzer gesetzt.
420_cre_table_frontent_log / 430_cre_table_frontent_log (/sql/base)
Erstellen der Strukturen für die durch den Dataprocessor erstellten Daten für das Frontend zum dauerhaften Speichern im Schema db_log. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
440_cre_table_frontent_in (/sql/base)
Erstellen der Strukturen im Schnittstellenschema db2frontend_in um Daten vom Modul Frontend (wieder) entgegen zu nehmen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
450_cre_table_frontend_in_trig
Zusätzlich zu den Tabellen in Skript 44 - Trigger welche den Datensätzen die erstmalig im Frontend erzeugt eine eindeutige primary key in der Datenbank setzen.
460_cre_view_fe_dataproc_last (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um die aktuellesten Studiendaten dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
461_cre_view_fe_dataproc_all (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um alle Studiendaten (inc. Historische) dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
462_cre_view_fe_dataproc_last_version (/sql/base)
Erstellt Views im Schnittstellenschema db2dataprocessor_out um alle Studiendaten in ihrer letzten Version darzustellen (ohne Historische) dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
470_cre_view_fe_dataproc_last (/sql/base)
Erstellt Views im Schnittstellenschema db2frontend_out um die aktuellesten Studiendaten dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
471_cre_view_fe_dataproc_all (/sql/base)
Erstellt Views im Schnittstellenschema db2frontend_out um alle Studiendaten (inc. Historische) dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
472_cre_view_fe_dataproc_last_version (/sql/base)
Erstellt Views im Schnittstellenschema db2frontend_out um alle Studiendaten in ihrer letzten Version darzustellen (ohne Historische) dem Modul Dataprocessor zur Verfügung zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
520_cre_view_fe_out (/sql/base)
Erstellt Views im Schnittstellenschema db2frontend_out um aktuelle Daten aus dem Kern dem Frontend zur Übergabe bereit zu stellen. Enthält auch die Vergabe der benötigten Berechtigungen für die zugehörigen Datenbanknutzer.
600_dp_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_fe_dp_in_to_db_log) für die Studiendaten (Frontend) vom Schnittstellenschema db2dataprocessor_in in den Kern (db_log) zur dauerhaften speicherung. Nach anlegen der Funktion wird ebenfalls der Cron-Job angelegt und gestartet, der die Funktion regelmäßig ausführt.
620_fe_in_to_db_log (/sql/base)
Erstellt die Überführungsfunktion (db.copy_fe_fe_in_to_db_log) für die Studiendaten (Frontend) vom Schnittstellenschema db2frontend_in in den Kern (db_log) zur dauerhaften speicherung. Nach anlegen der Funktion wird ebenfalls der Cron-Job angelegt und gestartet, der die Funktion regelmäßig ausführt.
950_cro_job (/sql/base)
Erstellt eine zentralen cron-job der alle Überführungsfunktionen der Datenbank steuert und ausführt.
980_dev_and_test (/sql/base)
Anlegen von Hilfstabellen für Tests und Entwicklung - nicht Produktiv.
Migration (start.sql)
Wenn es eine Neuer Version der Datenbank gibt (z.B. nach aktualiesierung des Frontends) oder bei Initialisierung der Datenabnk ist die Strukturen und Funktionalität (neu) zu erzeugen. Dies wird durch ausführen eines start-Skriptes welches sich im SQL-Hauptpfad befindet (SQL-Skripte)](https://github.com/medizininformatik-initiative/INTERPOLAR/tree/main/Postgres-cds_hub/sql/start.sql)) realisiert. Dabei wird die Version der Datenbank auf den aktuellen ausgecheckten Versions-Stand gehoben, wenn dieser neuer ist als die bisherige Version. Bei der Migration werden neue Spalten hinzugefügt, alte Spalten die nicht mehr dokumentiert werden, bleiben erhalten.
docker compose exec -w /cds_hub-initdb.d cds_hub psql -U cds_hub_db_admin -d cds_hub_db -f ./start.sql
Das start-Skript enthält die Referenz zu allen aktuellen SQL-Skripten in der richtigen Reihenfolge welche für die jeweilige Version notwendig sind.
start (/sql)
Skript welches alle Notwendigen Skripte zur Initialisierung/Migration ausführt und die Datenbank auf aktuellen Stand bringt.
000_stop_semapore_during_migration (/sql/base)
Verarbeitung der Datenbank wird angehalten damit Migration durchgeführt werden kann.
999_start_semapore_after_migration (/sql/base)
Verarbeitung der Datenbank wird normal gestartet nach Abschluss der Migration.
Namenskonvention Views und Tabellen
In der Datenbank gibt es für verschiedene Aufgaben verschiedene Views welche auf dieselbe Datenquelle zugreifen. Um diese voneinander zu unterscheiden werden den Tabellen/Views verschiedene Pre- und Postfix hinzugefügt. Aufgrund der begrenzten Zeichenanzahl geben diese teilweise nicht eine vollständige Beschreibung, sondern nur Hinweise (Genaue Funktionalität ist im SQL-Skript/Code nachzulesen). _raw - Tabellen/Views mit diesem Postfix beinhalten Raw-Daten - ohne diesen Postfix sind es typisierte Daten *_[Bedingung] - Wenn Einschränkende Bedingungen vorhanden sind, werden diese als Stichwort genannt (z.B. Last, Diff,…)