Implementation Guide Pseudonymization Interface for the MII - Local Development build (v2026.1.0) built by the FHIR (HL7® FHIR® Standard) Build Tools. See the Directory of published versions
Use Cases
- Use Case 1: Erzeugung und Verwaltung von Personenpseudonymen auf Basis vorhandener Identifier
- Use Case 2: Ersetzung von personenidentifizierenden Informationen in einem Datenbestand durch Personenpseudonyme
- Use Case 3: Sekundärpseudonymisierung
- Use Case 4: Pseudonymisierung durch Modifikation von Forschungsdaten
- Hinweise zur möglichen Umsetzung von Use Case 3b - Übergreifende Sekundärpseudonymisierung mit standortübergreifenden Record Linkage
Anmerkung: Für ein möglichst ganzheitliches Bild werden an dieser Stelle die Pseudonymisierung von Forschungsdaten betreffende Use Cases erläutert. Für die eigentliche Spezifikation der Schnittstelle jedoch sind die Use Cases 2 und 4 Out-of-Scope.
Use Case 1: Erzeugung und Verwaltung von Personenpseudonymen auf Basis vorhandener Identifier
Eine Person wurde bereits anhand von demografischen Informationen und ggf. vorhandenen lokalen Kennungen (z.B. SAP-ID, Fallnummer) eindeutig identifiziert und es wurde für diese Person ein eindeutiger Identifier (z.B. PID, Master Person Index) erzeugt. Für einen ausgewählten Kontext (z.B. DIZ-Pseudonym) wird ein Personenpseudonym erzeugt und dem vorhandenen eindeutigen Identifier zugeordnet. Das MII-Datenschutzkonzept (v. 1.01) gibt diese Verlinkung vor.
Beispiel:

Das verwaltende System erlaubt unter Angabe des Eingang-Identifiers und des Kontexts das bereits zugeordnete Personenpseudonym abzufragen (Pseudonymisierung). Gleichzeitig erlaubt das verwaltende System unter Angabe des Personenpseudonyms und des Kontexts den ursprünglichen Eingangs-Identifier abzufragen (Depseudonymisierung).
Use Case 2: Ersetzung von personenidentifizierenden Informationen in einem Datenbestand durch Personenpseudonyme
Out of Scope: Dieser Use Case wird durch die vorliegende Schnittstellenspezifikation nicht abgedeckt.
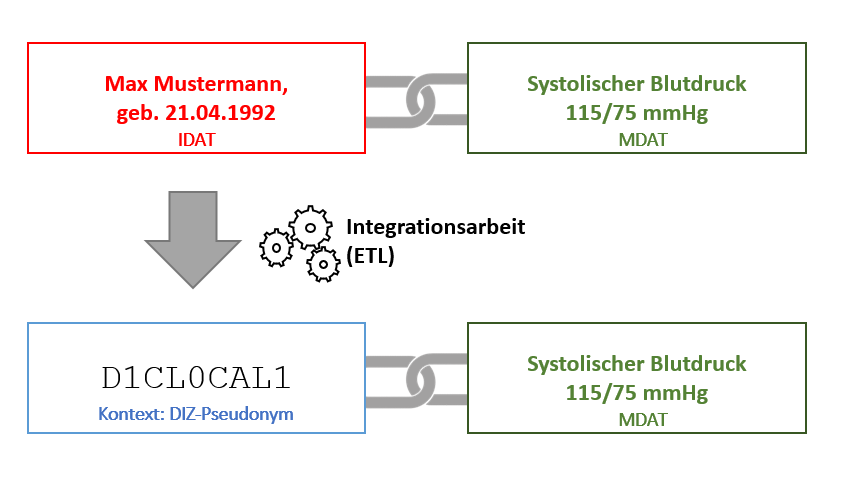
In einem medizinischen Datensatz sollen personenidentifizierende Informationen (Klartext) durch ein entsprechendes Personenpseudonym (z.B. DIZ-Pseudonym) ersetzt werden, um den Datensatz pseudonymisiert in einer lokalen Forschungsdatenbank am Standort speichern zu können.
Das Personenpseudonym wurde durch einen entsprechenden Prozess am Standort erzeugt (vgl. Use Case 1). Die Ersetzung (personenidentifizierende Informationen Personenpseudonym) wird durch individuelle Integrationsarbeit / ETL-Prozesse am ausführenden ermöglicht. Die Rückführbarkeit ist stets gegeben.
Beispiel:
Use Case 3: Sekundärpseudonymisierung
Für einen Datenverarbeitungsprozess (z.B. Datenweitergabe für Auswertungen) ist der Austausch eines vorhandenen Personenpseudonyms durch ein neues Kontext-sensitives Personenpseudonym in einem bestehenden medizinischen Datensatz erforderlich. Dieser Pseudonymisierungsschritt ist im Bedarfsfall jederzeit umkehrbar (De-Pseudonymisierung).
Use Case 3a: Sekundärpseudonymisierung ohne standortübergreifendes Record Linkage
Die Erzeugung der nötigen Sekundärpseudonyme kann lokal am MII-Standort (ohne standortübergreifendes Record Linkage) erfolgen.
Das Vorgehen setzt sich im Kern aus zwei Schritten (vgl. Use Case 1 und 2) zusammen:
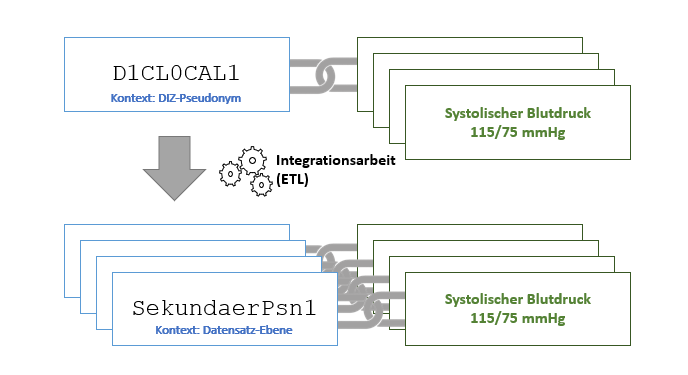
Schritt 1 Lokale Erzeugung von Sekundärpseudonymen:
Für jede Datenherausgabe wird lokal ein neues Personenpseudonym erzeugt (bzw. abgefragt) und dem vorhandenen lokal erzeugtem Personenpseudonym zugeordnet. Zusätzlich wird, wie in den MII-Konzepten definiert (vgl. MII-Datenschutzkonzept_v1.0), je herauszugebendem Datensatz bzw. je Bioprobe ein Sekundärpseudonym erzeugt und dem Datenherausgabepseudonym zugeordnet. Die Pseudonymhierarchie der Person enthält somit mehrere Sekundärpseudonyme und wird dadurch kontinuierlich erweitert. Die Rückführbarkeit ist stets gegeben

Schritt 2 Im medizinischen Exportdatensatz werden vorhandene Personen-Pseudonyme durch datensatz-spezifisch erzeugte Sekundärspseudonyme ersetzt
Die Ersetzung des vorhandenen lokalen Personenpseudonyms in den herauszugebenden Datensätzen durch entsprechende Sekundärpseudonyme (unterschiedliche Sekundärpseudonyme je Datensatz) wird durch individuelle Integrationsarbeit / ETL-Prozesse am ausführenden Standort ermöglicht. Die Rückführbarkeit ist stets gegeben.
Use Case 3b: Sekundärpseudonymisierung mit standortübergreifendem Record Linkage
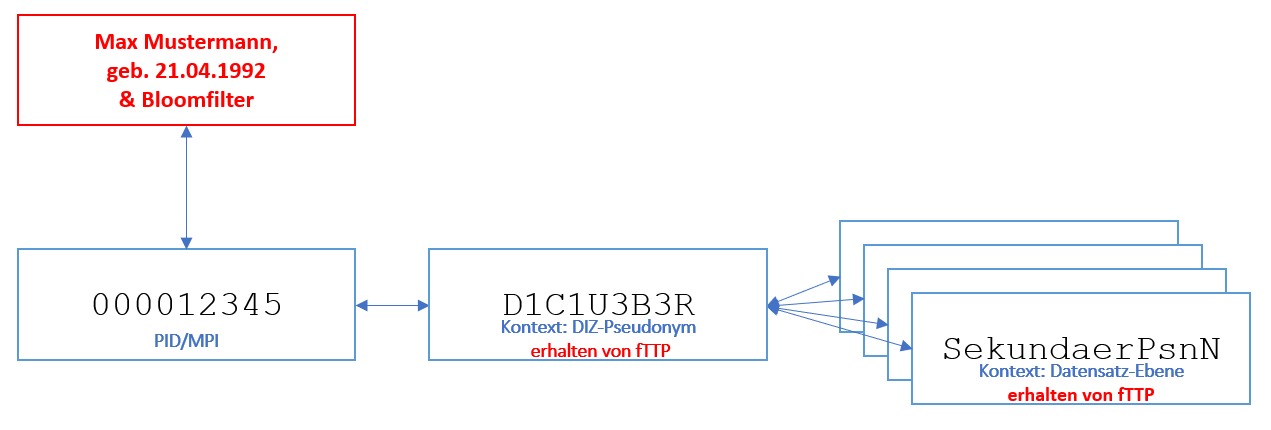
Die Erzeugung der nötigen Sekundärpseudonyme erfolgt im Kontext übergreifender MII-Prozesse über eine federated Trusted Third Party (fTTP) (vgl. Dokument MII Gesamtinfrastruktur), welche sicherstellt, dass Pseudonyme einheitlich und eindeutig erzeugt werden. Dafür ist es erforderlich, dass ein Standort bei Datenherausgaben einen projektspezifischen Bloomfilter auf Basis der identifizierenden Daten erzeugt und diesen bei der fTTP registriert. Dort erfolgt ein standortübergreifendes (Privacy-Preserving) Record Linkage. Im Ergebnis erhält der Standort ein projektspezifisches und übergreifend eindeutiges Pseudonym für die Person. Für Datenherausgaben können Sekundärpseudonyme bei der fTTP angefordert werden, welche dem zuvor erhaltenen Personenpseudonym zugeordnet werden.
Use Case 4: Pseudonymisierung durch Modifikation von Forschungsdaten
Out of Scope: Dieser Use Case wird durch die vorliegende Schnittstellenspezifikation nicht abgedeckt.
Dieses Use Case fokussiert die Erreichung eines pseudonymen Datenbestands durch Reduktion des eventuell vorhandenen Personenbezug innerhalb der medizinischen Forschungsdaten. Dabei umfasst der Begriff „Part-Anonymisation“ exemplarisch die Veränderung von Datenfeldern (Setzen von Standardwerten), eine Teildatenaggregation oder auch das Ausblenden von Teilinformationen. Hingegen umfasst der Begriff „Minimalisation” indes die Größenreduktion von FHIR-Ressourcen durch Entfernung nicht für die anvisierte Auswertung relevanter Datenelemente.
Hinweise zur möglichen Umsetzung von Use Case 3b - Übergreifende Sekundärpseudonymisierung mit standortübergreifenden Record Linkage
Das standortübergreifende Record Linkage findet mittels fTTP/übergreifender Treuhandstelle (üTHS) statt. Bei übergreifenden Projekten mit Anbindung einer Datenmanagementstelle und üTHS sieht das MII-Datenschutzkonzept (Entwurfsstand vom 27.05.2024, siehe Kapitel 6.2.6.2 Pseudonymisierung, Abbildung 6) unter anderem folgende Anbindungen vor:
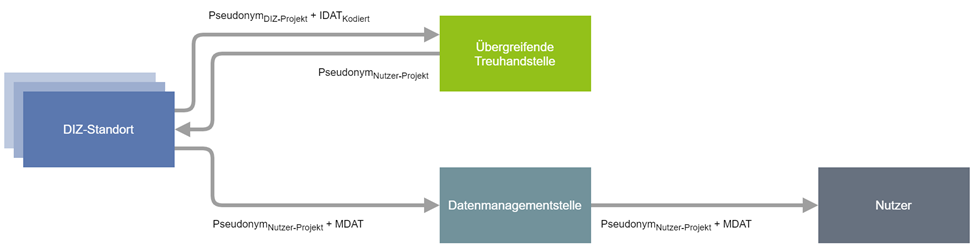
Das Pseudonym "Nutzer-Projekt" betitelt dabei das Pseudonym, welches von der fTTP/üTHS auf Basis des Record Linkages vergeben wird (z.B. ”D1C1U3B3R”)
Geltende Voraussetzungen:
- Für die Person wurden im Vorfeld auf Basis ein Record Linkage auf Basis von IDAT am Standort durchgeführt und es wurden Bloomfilter (Konfiguration nach Projektvorgabe) erzeugt.
- Für die Person wurde bereits ein übergreifendes Record Linkage auf Basis des Bloomfilters durchgeführt und ein für den Standort eindeutiges übergreifendes Personenpseudonym erzeugt und zugeordnet (z.B. „D1C1U3B3R“). Beide Schritte können beispielsweise durch eine fTTP erfolgen.
- Für die Person liegen n med. Datensätze vor.
Möglicher Ablauf Konkrete Abläufe können sich je Projektvorgabe unterscheiden:
- Die Erstellung der Sekundärpseudonyme erfolgt mittels Operation
$pseudonymize unter Angabe des count-Parameters. Dabei kann die erforderliche Funktionalität lokal oder auch föderiert bereitgestellt und genutzt werden. Es ist keine zusätzliche Schnittstelle/Schnittstellenfunktionalität hinaus erforderlich. Der Unterschied liegt allein im Ablauf. - Die abschließende Ersetzung des bisherigen Personenpseudonyms in den herauszugebenden Datensätzen durch die erzeugten Sekundärpseudonyme (vgl. Use Case 3a, Schritt 2) wird durch individuelle Integrationsarbeit / ETL-Prozesse am ausführenden Standort vorgenommen.
Anzusprechender Endpunkt der Schnittstelle: je nach Projektvorgabe lokaler Schnittstellen-Endpunkt am Standort oder fTTP